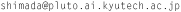研究内容
マルチモーダルインタフェース
複数の認識器を選択的もしくは統合的に扱う音声理解手法について研究しています.特性の異なる認識器を組み合わせることで,ノイズにも頑健な音声認識結果を得ることが可能になります.また,複数の音声認識器の結果を利用し,文中の省略要素の補完を行うような文脈処理も行っています.さらに,辞書を階層化することで,より効率的で,精度の高い音声理解手法について研究をしています
上記の音声理解手法とハンドジェスチャを組み合わせたマルチモーダルインターフェースについて研究をしています.ハンドジェスチャ認識では,逐次的に学習をしていくことで,環境や学習データに存在しない人物でも高精度に分類できるような手法を提案しています. また,ハンドジェスチャだけでなく,動画像と音情報から目の前にいる人が現在発話しているのかの判定や顔の一部がマスクなどで隠れていても,着ている服や場所などの文脈情報を利用して誰かを同定する人物識別手法についても研究を進めています.
■マーカを利用したハンドジェスチャインタフェース
■手形状と音声による入力インタフェース

Keywords:音声理解,ジェスチャ認識,対話処理
Webからの情報抽出
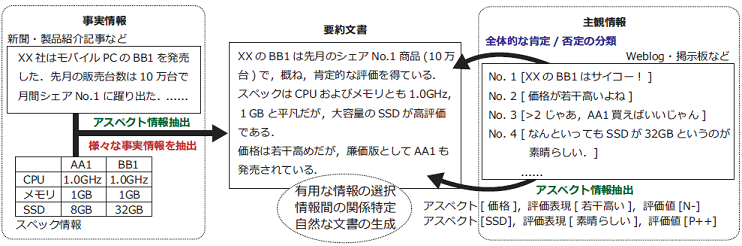
Web上のレビューサイトや批評サイトなどから,評価表現を抽出する手法について研究しています.さらに文章や文書の内容が肯定的な意見なのか,それとも否定的な意見なのかをヒューリスティックスやスコア計算,機械学習アルゴリズムを利用して分類する手法についても研究しています.精度の高い分類器を実現するために,複数の分類器を組み合わせる手法について考察しています.また,肯定か否定かの2値だけでなく,より細かい分類(例えば,5段階評価で何点か)まで推定するタスクについても研究を進めています.
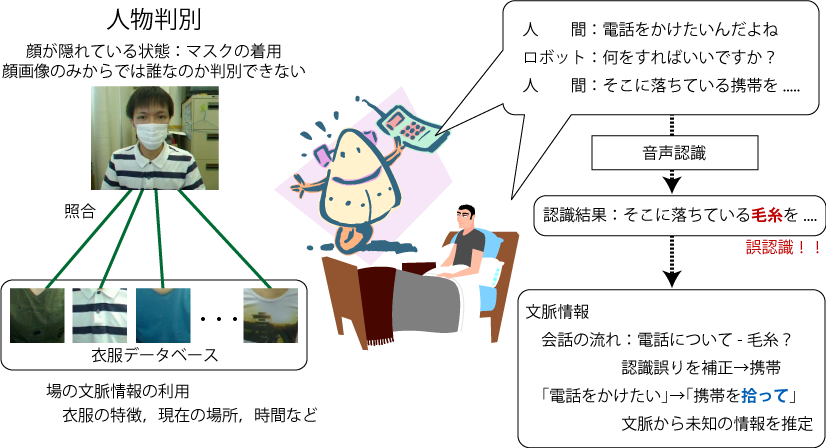
評判情報のような主観的な情報とスペック情報などの客観的な情報を統合した要約モデルの構築を進めています.単に大きな文書をコンパクトにするのではなく,情報源の持つアスペクト(たとえば,PCならば,拡張性や操作性など)に着目し,より内容を把握しやすい要約の生成を目指しています.また,要約処理の中に対話的なユーザとのやりとりを導入し,動的に,内容を編纂し直す手法についても研究を進めています.
Keywords:情報抽出,情報の可視化,評判検索,要約処理
九州工業大学 情報工学部 遠藤研究室